Aplicación independiente de Codex (Codex App)
Instala y configura Mole API como proveedor de modelos en la aplicación independiente de Codex. Solo necesitas iniciar sesión con tu API Key y editar `config.toml` para empezar a usarlo.
Introducción del proyecto
La aplicación independiente de Codex (Codex App) es el cliente de escritorio de Codex y ofrece las mismas capacidades de conversación con IA y asistencia de programación que el complemento de Codex en VS Code. En la aplicación independiente puedes chatear, completar código y obtener explicaciones sin necesidad de abrir el editor. Al configurar Mole API como proveedor de modelos, puedes usar una clave unificada y una gestión centralizada del consumo.
- Sitio web oficial y descarga: https://openai.com/codex
Escenarios de uso
- Usas la aplicación independiente de Codex (Codex App) y quieres utilizar en ella las capacidades de conversación y de IA de Codex.
- Quieres usar Mole API como punto de acceso de modelos para Codex y gestionar de forma unificada el consumo y las claves.
Requisitos previos
- Ya has obtenido tu API Key en el panel de administración de Mole API (genérala y cópiala desde la página del centro personal o de gestión de tokens).
Paso 1: descargar e instalar Codex
- Abre el navegador y visita el sitio web oficial de Codex: https://openai.com/codex。
- Sigue las instrucciones de la página para descargar e instalar la aplicación Codex.
Una vez finalizada la instalación, inicia la aplicación Codex.
Paso 2: iniciar sesión con API Key
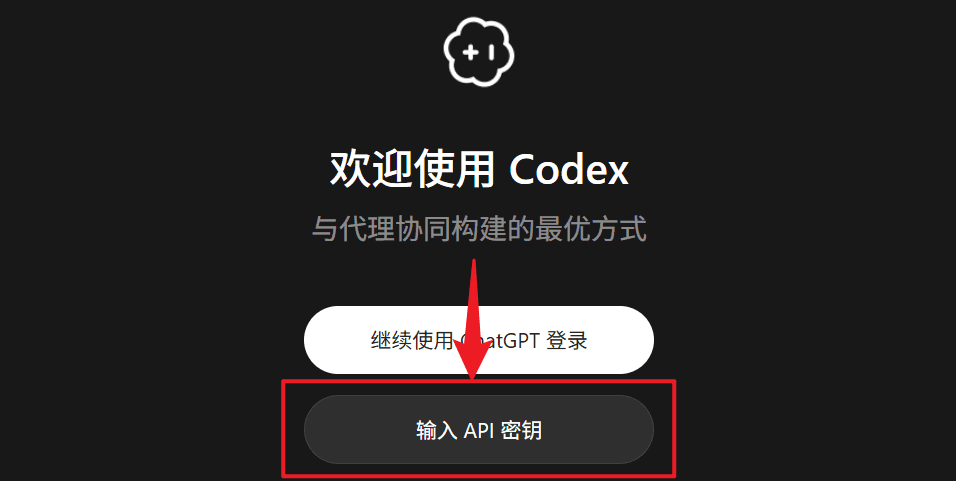
- En la aplicación Codex, selecciona el método de inicio de sesión/autenticación mediante API Key.
- Introduce la API Key que obtuviste en el panel de administración de Mole API.
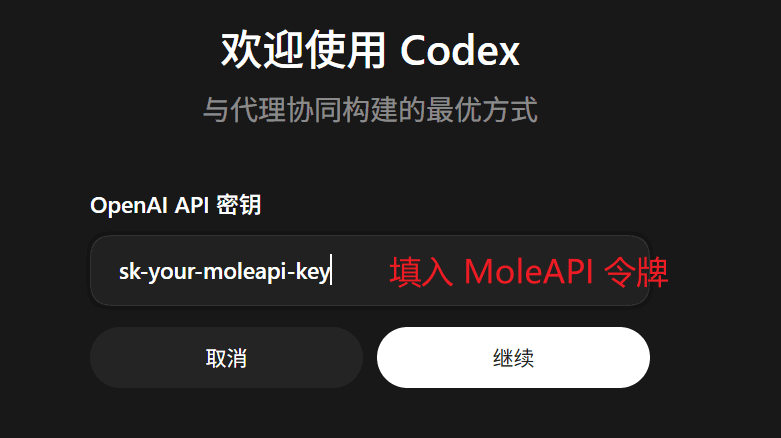
Aquí solo se completa la introducción de la clave. Para que Codex envíe realmente solicitudes a Mole API, también debes especificar el proveedor de modelos en la configuración.
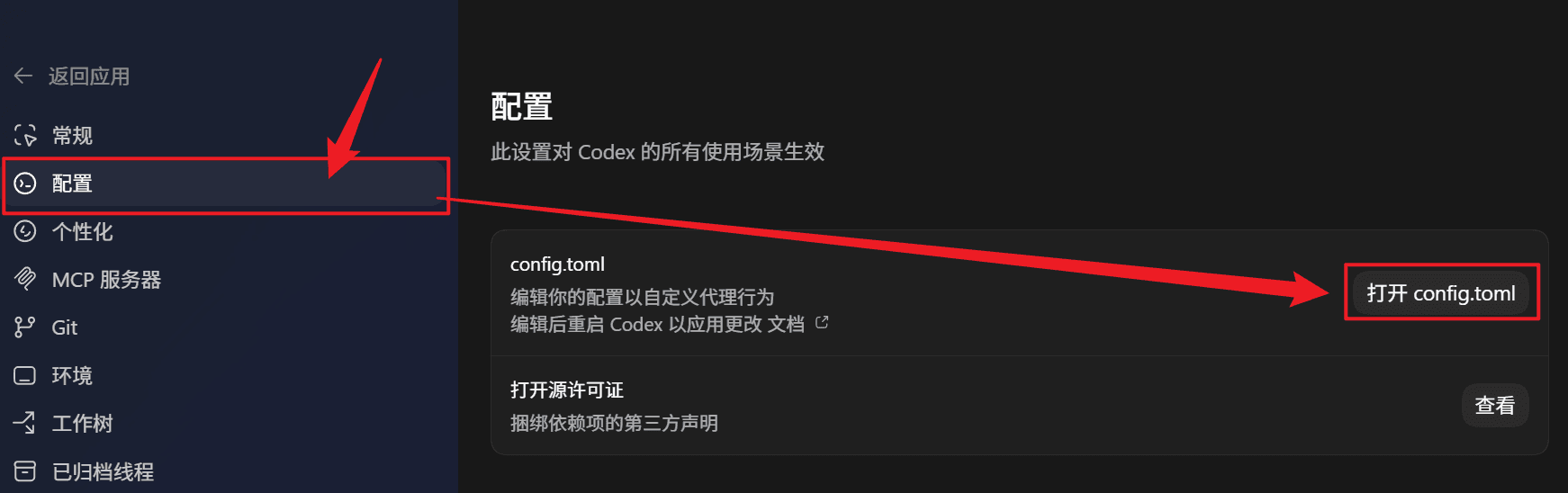
Paso 3: abrir los ajustes y seleccionar la configuración
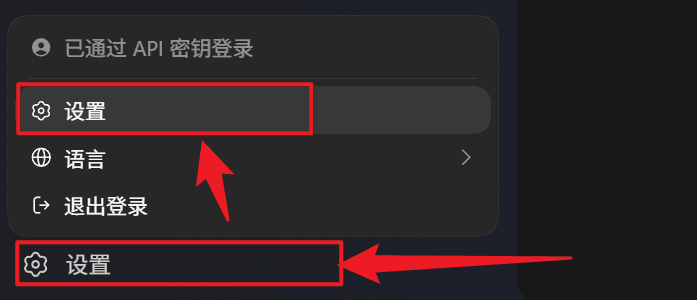
- Después de iniciar sesión, abre Ajustes → Ajustes.
- En los ajustes, selecciona Configuración y abre
config.toml.
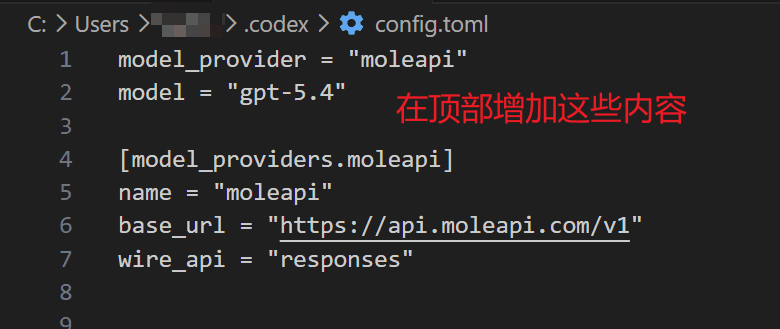
Paso 4: configurar Mole API en config.toml
Añade el siguiente contenido en el config.toml abierto:
model_provider = "moleapi"
[model_providers.moleapi]
name = "moleapi"
base_url = "https://api.moleapi.com/v1"
wire_api = "responses"También puedes añadir model = "el modelo de moleapi que quieras usar, por ejemplo claude-opus-4-6".
Después de guardar config.toml, reinicia Codex para que la configuración surta efecto.
Paso 5: verificar si la configuración se ha realizado correctamente
- Abre Codex de nuevo y envía un mensaje en el cuadro de entrada (por ejemplo, «Hola»).
- Si Codex responde con normalidad y puedes ver en el registro de solicitudes del panel de administración de Mole API las solicitudes correspondientes a esa API Key, significa que Mole API se ha configurado correctamente como proveedor de modelos de Codex.
Preguntas frecuentes
Al enviar un mensaje no hay respuesta o aparece un error
- Verifica que
model_provider = "moleapi"y[model_providers.moleapi]estén correctamente configurados y guardados enconfig.toml. - Verifica que base_url sea
https://api.moleapi.com/v1; no olvides/v1ni añadas rutas adicionales. - Verifica que la API Key introducida coincida con la del panel de administración de Mole API y que no haya caducado. Después de modificar la configuración, debes reiniciar Codex.
Quiero cambiar de modelo o endpoint
En el panel de administración de Mole API puedes gestionar los modelos disponibles y el consumo. Si en Codex necesitas cambiar el endpoint o el proveedor, puedes ajustar model_provider y la configuración correspondiente de [model_providers.*] en config.toml, y después reiniciar Codex.
Enlaces de referencia
¿Te resultó útil esta guía?
Última actualización el
Aplicaciones de AI
Aplicaciones de AI compatibles y opciones de integración
AionUi - Agent de oficina de escritorio gratuito y de código abierto
Tutorial de AionUi — Agent de oficina de escritorio gratuito y de código abierto, compatible con Gemini CLI, Claude Code, Codex y otros AI agents. Integración con MoleAPI para implementar flujos de trabajo multimodelo.