Ratio の理解
Ratio の設定は、MoleAPI の課金システムにおける中核的な設定です。モデル Ratio、補完 Ratio、キャッシュ Ratio、グループ Ratio を理解すると、料金ページに表示されている Ratio 情報を読み取れるようになり、ログをもとに「なぜこのリクエストでこれだけ差し引かれたのか」をすばやく照合できるようになります。
Ratio システムの概要
MoleAPI では、ユーザーの Quota 消費を計算するために 4 種類の Ratio を使用します。
- モデル Ratio(
ModelRatio):モデル自体の基本課金倍率を定義します - 補完 Ratio(
CompletionRatio):出力 token の価格を個別に調整します - キャッシュ Ratio(
CacheRatio):キャッシュヒットした入力 token の価格を個別に調整します - グループ Ratio(
GroupRatio):異なるグループごとに差別化された課金を設定します
Quota と Ratio の関係
MoleAPI では、最終的な課金はすべて Quota ポイントに換算されます。
1 ドル = 500,000 Quota ポイント- ユーザー残高や消費履歴は、本質的には Quota ポイントの増減です
- ログではドル表記の明細がよく使われますが、バックエンドでは最終的に Quota ポイントへ換算して差し引かれます
Quota の計算式
従量課金モデル(キャッシュヒットなし)
Quota 消費 = (入力 token 数 + 出力 token 数 × 補完 Ratio) × モデル Ratio × グループ Ratio従量課金モデル(キャッシュヒットあり)
キャッシュヒット時は、「キャッシュ Ratio」を総額全体に追加で掛けるのではなく、キャッシュされた入力 token の部分にのみ適用されます。
Quota 消費 = (通常入力 token 数 + キャッシュ token 数 × キャッシュ Ratio + 出力 token 数 × 補完 Ratio) × モデル Ratio × グループ Ratio回数課金モデル(固定価格)
Quota 消費 = モデル固定価格 × グループ Ratio × 500,000音声モデル(特別処理、new-api 内部で自動処理)
Quota 消費 = (テキスト入力 token + テキスト出力 token × 補完 Ratio + 音声入力 token × 音声 Ratio + 音声出力 token × 音声 Ratio × 音声補完 Ratio) × モデル Ratio × グループ Ratio事前消費と事後消費の仕組み
MoleAPI では、事前消費と事後消費の 2 段階課金を採用しています。
- 事前消費:リクエスト送信前に、見積もり token 数に基づいて先に仮引き落としします
- 事後消費:リクエスト完了後に、実際の token 数で再計算します
- 差額調整:実際の費用と仮引き落とし額が一致しない場合は、自動で追加徴収または返却します
事前消費 Quota = 見積もり token 数 × モデル Ratio × グループ Ratio
実際 Quota = 実際の token 数 × モデル Ratio × グループ Ratio
Quota 調整 = 実際 Quota - 事前消費 Quotaモデル Ratio の設定
モデル Ratio は、異なる AI モデルの基本課金倍率を定義します。システムでは、一般的なモデルに対してあらかじめデフォルト値が設定されています。
一般的なモデル Ratio の例
| モデル名 | モデル Ratio | 補完 Ratio | 公式価格(入力) | 公式価格(出力) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
Ratio の意味は、次のように理解できます。
- モデル Ratio が高いほど、全体の基本コストは高くなります
- 補完 Ratio が高いほど、出力 token は高くなります
- キャッシュ Ratio が低いほど、キャッシュヒット時のコスト削減効果は大きくなります
- グループ Ratio が低いほど、ユーザーに対する最終的な実際の課金額は低くなります
補完 Ratio の設定
補完 Ratio は、出力 token に対して追加課金を行うために使用されます。これは主に、「出力は入力より高い」という実際のコスト差を反映するためです。
デフォルトの補完 Ratio
| モデルタイプ | 公式価格(入力) | 公式価格(出力) | 補完 Ratio | 説明 |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | 出力は入力の 4 倍 |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | 出力は入力の 2 倍 |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | 出力は入力の 8 倍 |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | 出力は入力の 4 倍 |
| その他のモデル | 1 | 1 | 1 | 入出力を同一料金で課金 |
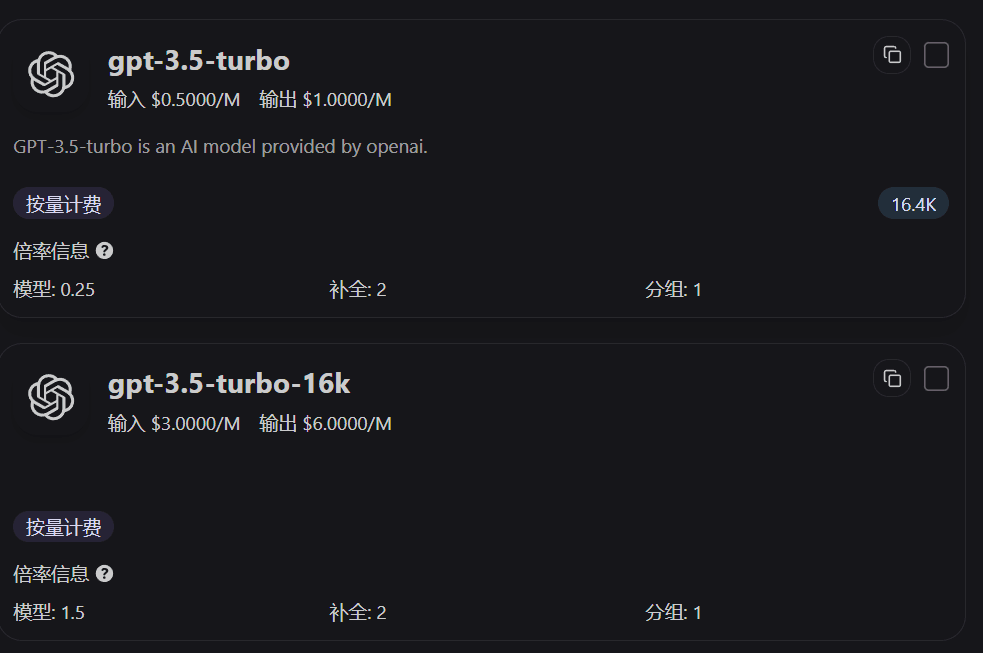
料金ページで Ratio を確認する方法
料金ページのモデルカードには、モデル Ratio、補完 Ratio、グループ Ratio が直接表示されます。まずこの 3 つの値を見ることで、「同じ 1 回の呼び出しなのに、なぜこのモデルは別のモデルより高いのか」をすばやく判断できます。
キャッシュ Ratio の設定
キャッシュ Ratio は、多くの人が初めてログを見たときに最も誤解しやすいポイントです。
キャッシュ Ratio はどこに適用されるのか
これはキャッシュヒットした入力 tokenにのみ適用され、次には適用されません。
- キャッシュヒットしていない通常の入力 token
- 出力 token
- リクエスト全体の総額
つまり、1 件のリクエスト内に通常入力とキャッシュ入力が同時に存在する場合、それぞれ異なる価格で計算された後、まとめてグループ Ratio が掛けられます。
どのような場合にログでキャッシュ Ratio が表示されるか
上流モデルがプロンプトキャッシュをサポートしており、かつ今回のリクエストで実際にキャッシュヒットした場合、ログには通常、追加で次の項目が表示されます。
キャッシュ Tokensキャッシュ Ratioキャッシュ価格
キャッシュヒットしなかった場合、これらの行は最終費用の計算には参加しません。
グループ Ratio の設定
グループ Ratio を使用すると、異なる Channel グループごとに差別化された価格を設定でき、たとえばデフォルトグループ、割引グループ、転送グループ、試用グループなど、異なる戦略を実現できます。
グループ Ratio の設定例
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}Q:グループ Ratio はどのように適用されますか?
A:グループ Ratio は、最終段階でリクエスト全体に対して一括で適用されます。これは「最終的にユーザー向けに適用される価格係数」と考えることができます。
Q:補完 Ratio の役割は何ですか?
A:補完 Ratio は主に、入力 token と出力 token のコスト差を調整するために使用されます。多くのモデルでは出力価格が入力価格より明らかに高いため、ログでは出力 token が補完 Ratio に基づいて個別換算されます。
Q:キャッシュ Ratio の役割は何ですか?
A:キャッシュ Ratio は、キャッシュヒットした入力 token にのみ影響します。キャッシュ Ratio が低いほど、キャッシュヒット時のその部分の実コストは低くなります。
QA 計算例
以下の例は抽象的な数式ではなく、ログ内のフィールドに基づいて 1 ステップずつ直接計算したものです。
Q1:キャッシュ付きのリクエストで、なぜログに「キャッシュ価格」という行が追加で表示されるのですか?
これは今回のリクエストでキャッシュヒットしたためで、システムが入力 token を 2 つの部分に分けているからです。
- 通常の入力 token:入力価格で計算
- キャッシュヒットした token:入力価格にキャッシュ Ratio を掛けて計算
以下のログでは、キャッシュ Tokens 3072、キャッシュ Ratio 1、キャッシュ価格 を確認できます。

ログ内の数値に基づく計算は次のとおりです。
入力費用 = 62 / 1M × $0.250000 = $0.0000155
キャッシュ費用 = 3072 / 1M × $0.250000 = $0.000768
出力費用 = 1193 / 1M × $2.000000 = $0.002386
最終費用 = (入力費用 + キャッシュ費用 + 出力費用) × グループ Ratio 1
= $0.0031695
≈ $0.003170これを Quota ポイントに換算すると、おおよそ次のとおりです。
$0.003170 × 500,000 ≈ 1,585 Quota ポイントQ2:キャッシュヒットがない場合、費用はどのように照合すればよいですか?
キャッシュヒットがない場合は、通常入力と出力の 2 つだけを見ればよく、キャッシュ価格は表示されません。

ログ内のフィールドに対応する計算は次のとおりです。
入力費用 = 827 / 1M × $0.250000 = $0.00020675
出力費用 = 338 / 1M × $2.000000 = $0.000676
最終費用 = (入力費用 + 出力費用) × グループ Ratio 1
= $0.00088275
≈ $0.000883Quota ポイントに換算すると、おおよそ次のとおりです。
$0.000883 × 500,000 ≈ 441 Quota ポイントQ3:キャッシュ Ratio とグループ Ratio が同時にある場合、どちらを先に計算すべきですか?
まず入力、キャッシュ、出力の 3 つの費用をそれぞれ計算し、その後でまとめてグループ Ratio を掛けます。以下のログには、同時に次の値が含まれています。
- モデル Ratio
1.25 - キャッシュ Ratio
0.1 - 出力 Ratio
6 - グループ Ratio
0.3

ログの価格明細に基づく計算は次のとおりです。
通常入力費用 = 357360 / 1M × $2.500000 = $0.893400
キャッシュ費用 = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
出力費用 = 100 / 1M × $15.000000 = $0.001500
最終費用 = (通常入力費用 + キャッシュ費用 + 出力費用) × グループ Ratio 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736これが、ログ内で次の項目が個別表示される理由でもあります。
- 入力価格:
$2.500000 / 1M tokens - 出力価格:
$15.000000 / 1M tokens - キャッシュ価格:
$2.500000 × 0.1 = $0.250000 / 1M tokens
Q4:モデルカードの大まかな高低を Ratio から逆算するにはどうすればよいですか?
最もシンプルな順序は次のとおりです。
- まずモデル Ratio を見て、そのモデルの基本コストが高いかどうかを判断する
- 次に補完 Ratio を見て、出力内容が明らかに高くなるかどうかを判断する
- モデルがキャッシュをサポートしている場合は、さらにキャッシュ Ratio を見て、キャッシュヒット後にどれだけ節約できるかを判断する
- 最後にグループ Ratio を見て、現在のグループで実際にユーザー向けへ適用される価格を判断する
料金ページであるモデルについて次のように表示されている場合:
- モデル Ratio が高い
- 補完 Ratio が高い
- グループ Ratio も高い
そのモデルは、長い出力が発生するシナリオでは通常かなり高くなります。逆に、キャッシュ Ratio が低く、キャッシュヒット率が高い場合、その種のリクエストの実費用はより大きく下がります。
より多くの課金ルールについては、よくある質問 を参照してください。
このガイドはいかがですか?
最終更新日