Verständnis der Ratios
Die Ratio-Einstellungen sind die zentrale Konfiguration des Abrechnungssystems von MoleAPI. Wenn du Modell-Ratio, Completion-Ratio, Cache-Ratio und Group-Ratio verstanden hast, kannst du die Ratio-Angaben auf der Preisseite nachvollziehen und anhand der Logs schnell prüfen, warum bei einer Anfrage genau dieser Betrag abgezogen wurde.
Überblick über das Ratio-System
MoleAPI verwendet vier Arten von Ratios, um den Quota-Verbrauch der Benutzer zu berechnen:
- Modell-Ratio (
ModelRatio): Definiert den grundlegenden Abrechnungsfaktor des Modells selbst - Completion-Ratio (
CompletionRatio): Passt den Preis für Output-Token separat an - Cache-Ratio (
CacheRatio): Passt den Preis für Input-Token mit Cache-Treffer separat an - Group-Ratio (
GroupRatio): Definiert differenzierte Abrechnung für verschiedene Gruppen
Zusammenhang zwischen Quota und Ratios
In MoleAPI werden die endgültigen Kosten einheitlich in Quota-Punkte umgerechnet.
1 US-Dollar = 500.000 Quota-Punkte- Benutzerguthaben und Verbrauchsprotokolle sind im Kern Zu- und Abnahmen von Quota-Punkten
- In Logs sieht man häufig Details in US-Dollar; im Backend werden diese am Ende erneut in Quota-Punkte umgerechnet und abgezogen
Formel zur Quota-Berechnung
Usage-basierte Modelle (ohne Cache-Treffer)
Quota-Verbrauch = (Anzahl Input-Token + Anzahl Output-Token × Completion-Ratio) × Modell-Ratio × Group-RatioUsage-basierte Modelle (mit Cache-Treffer)
Bei einem Cache-Treffer wird die „Cache-Ratio“ nicht zusätzlich auf den Gesamtpreis multipliziert, sondern nur auf den Anteil der gecachten Input-Token angewendet.
Quota-Verbrauch = (Anzahl normale Input-Token + Anzahl Cache-Token × Cache-Ratio + Anzahl Output-Token × Completion-Ratio) × Modell-Ratio × Group-RatioRequest-basierte Modelle (Festpreis)
Quota-Verbrauch = Modell-Festpreis × Group-Ratio × 500.000Audio-Modelle (Sonderbehandlung, wird intern von new-api automatisch verarbeitet)
Quota-Verbrauch = (Text-Input-Token + Text-Output-Token × Completion-Ratio + Audio-Input-Token × Audio-Ratio + Audio-Output-Token × Audio-Ratio × Audio-Completion-Ratio) × Modell-Ratio × Group-RatioMechanismus für Vorabverbrauch und Nachberechnung
MoleAPI verwendet ein zweistufiges Abrechnungsmodell mit Vorabverbrauch und Nachberechnung:
- Vorabverbrauch: Vor dem Senden der Anfrage wird anhand der geschätzten Token zunächst ein Betrag vorab reserviert
- Nachberechnung: Nach Abschluss der Anfrage wird anhand der tatsächlichen Token neu berechnet
- Differenzanpassung: Wenn tatsächliche Kosten und vorab reservierte Kosten nicht übereinstimmen, wird automatisch nachbelastet oder zurückerstattet
Vorab-Quota = Geschätzte Anzahl Token × Modell-Ratio × Group-Ratio
Tatsächliche Quota = Tatsächliche Anzahl Token × Modell-Ratio × Group-Ratio
Quota-Anpassung = Tatsächliche Quota - Vorab-QuotaModell-Ratio konfigurieren
Die Modell-Ratio definiert den grundlegenden Abrechnungsfaktor verschiedener AI-Modelle. Das System hinterlegt für gängige Modelle Standardwerte.
Beispiele für gängige Modell-Ratios
| Modellname | Modell-Ratio | Completion-Ratio | Offizieller Preis (Input) | Offizieller Preis (Output) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
Die Bedeutung der Ratios lässt sich so verstehen:
- Je höher die Modell-Ratio, desto höher die gesamten Basiskosten
- Je höher die Completion-Ratio, desto teurer sind Output-Token
- Je niedriger die Cache-Ratio, desto mehr spart ein Cache-Treffer
- Je niedriger die Group-Ratio, desto geringer ist die tatsächliche Endabrechnung für den Benutzer
Completion-Ratio konfigurieren
Die Completion-Ratio dient dazu, Output-Token zusätzlich zu bepreisen. Sie bildet vor allem den realen Kostenunterschied ab, dass „Output teurer ist als Input“.
Standard-Completion-Ratios
| Modelltyp | Offizieller Preis (Input) | Offizieller Preis (Output) | Completion-Ratio | Beschreibung |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | Output ist 4× so teuer wie Input |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | Output ist 2× so teuer wie Input |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | Output ist 8× so teuer wie Input |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | Output ist 4× so teuer wie Input |
| Andere Modelle | 1 | 1 | 1 | Gleichwertige Abrechnung für Input und Output |
Wie man Ratios auf der Preisseite liest
Die Modellkarten auf der Preisseite zeigen direkt Modell-Ratio, Completion-Ratio und Group-Ratio an. Wenn du zuerst diese drei Werte ansiehst, kannst du schnell beurteilen, warum „derselbe Aufruf bei diesem Modell teurer ist als bei einem anderen“.
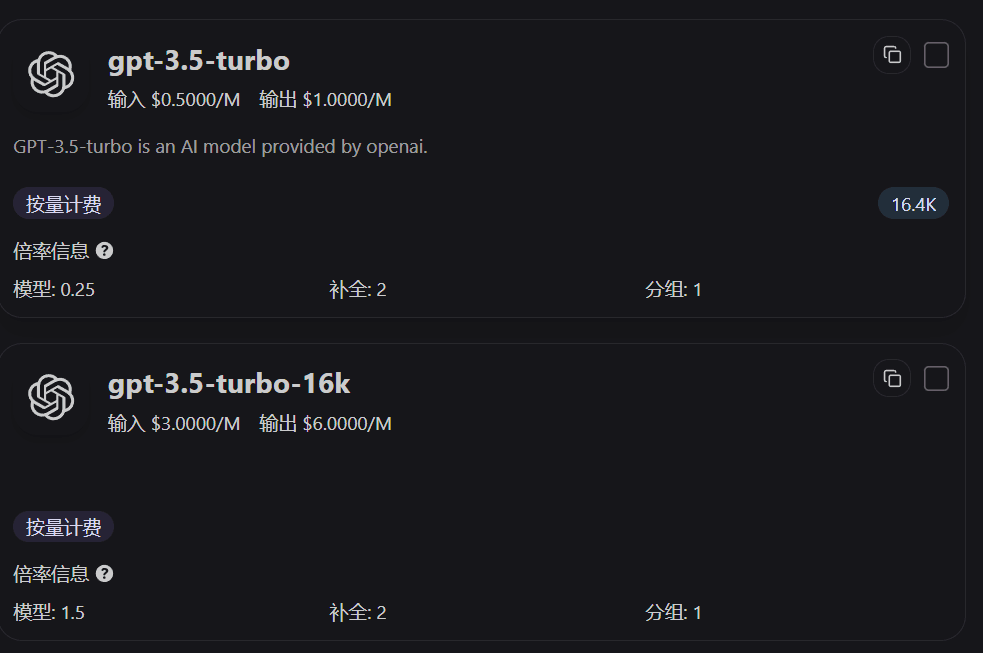
Cache-Ratio konfigurieren
Die Cache-Ratio ist der Punkt, der bei vielen beim ersten Blick in die Logs am leichtesten missverstanden wird.
Wo genau die Cache-Ratio wirkt
Sie wirkt nur auf Input-Token mit Cache-Treffer und nicht auf:
- normale Input-Token ohne Cache-Treffer
- Output-Token
- den Gesamtpreis der gesamten Anfrage
Das heißt: Wenn in einer Anfrage gleichzeitig normale Input-Token und gecachte Input-Token vorkommen, werden sie jeweils mit unterschiedlichen Preisen berechnet und erst danach gemeinsam mit der Group-Ratio multipliziert.
Wann du die Cache-Ratio in Logs siehst
Wenn das Upstream-Modell Prompt-Caching unterstützt und diese Anfrage tatsächlich einen Cache-Treffer hatte, sieht man im Log normalerweise zusätzlich:
缓存 Tokens缓存倍率缓存价格
Wenn kein Cache-Treffer vorliegt, fließen diese Zeilen nicht in die endgültige Kostenberechnung ein.
Group-Ratio konfigurieren
Die Group-Ratio ermöglicht differenzierte Preise für verschiedene Channel-Gruppen, z. B. Standardgruppe, Rabattgruppe, Relay-Gruppe oder Testgruppe.
Konfiguration der Group-Ratio
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}F: Wie wird die Group-Ratio angewendet?
A: Die Group-Ratio wird in der letzten Phase einheitlich auf die gesamte Anfrage angewendet. Du kannst sie als „endgültigen Preisfaktor für den Benutzer“ verstehen.
F: Wofür dient die Completion-Ratio?
A: Die Completion-Ratio dient hauptsächlich dazu, den Kostenunterschied zwischen Input- und Output-Token auszugleichen. Bei vielen Modellen ist der Output deutlich teurer als der Input, daher werden Output-Token in den Logs separat mit der Completion-Ratio umgerechnet.
F: Wofür dient die Cache-Ratio?
A: Die Cache-Ratio beeinflusst nur Input-Token mit Cache-Treffer. Je niedriger die Cache-Ratio, desto geringer sind die tatsächlichen Kosten dieses Token-Anteils bei einem Cache-Treffer.
QA-Berechnungsbeispiele
Die folgenden Beispiele sind keine abstrakten Formeln, sondern direkte Schritt-für-Schritt-Berechnungen anhand der Felder in den Logs.
F1: Warum erscheint bei einer Anfrage mit Cache im Log zusätzlich die Zeile „Cache-Preis“?
Weil diese Anfrage einen Cache-Treffer hatte und das System die Input-Token in zwei Teile aufgeteilt hat:
- normale Input-Token: berechnet zum Input-Preis
- Input-Token mit Cache-Treffer: berechnet zum Input-Preis multipliziert mit der Cache-Ratio
Im folgenden Log sieht man 缓存 Tokens 3072, 缓存倍率 1 und 缓存价格:

Anhand der Zahlen im Log ergibt sich folgende Berechnung:
Input-Kosten = 62 / 1M × $0.250000 = $0.0000155
Cache-Kosten = 3072 / 1M × $0.250000 = $0.000768
Output-Kosten = 1193 / 1M × $2.000000 = $0.002386
Endkosten = (Input-Kosten + Cache-Kosten + Output-Kosten) × Group-Ratio 1
= $0.0031695
≈ $0.003170Umgerechnet in Quota-Punkte sind das ungefähr:
$0.003170 × 500.000 ≈ 1.585 Quota-PunkteF2: Wie sollte man die Kosten prüfen, wenn es keinen Cache-Treffer gibt?
Ohne Cache-Treffer müssen nur normaler Input und Output betrachtet werden; ein Cache-Preis erscheint dann nicht.

Die Felder im Log ergeben folgende Berechnung:
Input-Kosten = 827 / 1M × $0.250000 = $0.00020675
Output-Kosten = 338 / 1M × $2.000000 = $0.000676
Endkosten = (Input-Kosten + Output-Kosten) × Group-Ratio 1
= $0.00088275
≈ $0.000883Umgerechnet in Quota-Punkte sind das ungefähr:
$0.000883 × 500.000 ≈ 441 Quota-PunkteF3: Wenn Cache-Ratio und Group-Ratio gleichzeitig vorhanden sind, was wird zuerst berechnet?
Zuerst werden die Kosten für Input, Cache und Output jeweils separat berechnet, danach wird einheitlich mit der Group-Ratio multipliziert. Das folgende Log enthält gleichzeitig:
- Modell-Ratio
1.25 - Cache-Ratio
0.1 - Output-Ratio
6 - Group-Ratio
0.3

Anhand der Preisdaten im Log ergibt sich:
Normale Input-Kosten = 357360 / 1M × $2.500000 = $0.893400
Cache-Kosten = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
Output-Kosten = 100 / 1M × $15.000000 = $0.001500
Endkosten = (Normale Input-Kosten + Cache-Kosten + Output-Kosten) × Group-Ratio 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736Genau deshalb wird im Log separat angezeigt:
- Input-Preis:
$2.500000 / 1M tokens - Output-Preis:
$15.000000 / 1M tokens - Cache-Preis:
$2.500000 × 0.1 = $0.250000 / 1M tokens
F4: Wie kann man aus den Ratios grob ableiten, ob eine Modellkarte teuer ist?
Die einfachste Reihenfolge ist:
- Zuerst die Modell-Ratio prüfen, um die Basiskosten des Modells einzuschätzen
- Dann die Completion-Ratio prüfen, um zu sehen, ob Output deutlich teurer wird
- Wenn das Modell Caching unterstützt, zusätzlich die Cache-Ratio prüfen, um das Einsparpotenzial bei Cache-Treffern zu bewerten
- Zum Schluss die Group-Ratio prüfen, um den tatsächlichen Endpreis für den Benutzer in der aktuellen Gruppe einzuschätzen
Wenn du auf der Preisseite bei einem Modell Folgendes siehst:
- hohe Modell-Ratio
- hohe Completion-Ratio
- ebenfalls hohe Group-Ratio
dann ist es in Szenarien mit viel Output in der Regel deutlich teurer. Umgekehrt sinken die tatsächlichen Kosten solcher Anfragen spürbarer, wenn die Cache-Ratio niedrig ist und die Cache-Trefferquote hoch ausfällt.
Weitere Abrechnungsregeln findest du unter Häufig gestellte Fragen
War diese Anleitung hilfreich?
Zuletzt aktualisiert am
Benachrichtigungseinstellungen und Quota-Warnungen
Frühzeitig über Guthaben- oder Anomaliehinweise informiert zu werden, ist wichtiger, als erst nach einem Serviceproblem mit der Fehlersuche zu beginnen
Schneller Einstieg für Entwickler
Den ersten minimal funktionsfähigen Aufruf mit einer OpenAI-kompatiblen Schnittstelle durchführen