Ratio 이해
Ratio 설정은 MoleAPI 과금 시스템의 핵심 구성입니다. 모델 Ratio, Completion Ratio, Cache Ratio, Group Ratio를 이해하면 가격 페이지에 표시된 Ratio 정보를 읽을 수 있고, 로그를 기준으로 특정 요청이 왜 그만큼 차감되었는지도 빠르게 확인할 수 있습니다.
Ratio 시스템 개요
MoleAPI는 사용자 Quota 소모를 계산하기 위해 네 가지 유형의 Ratio를 사용합니다.
- 모델 Ratio(
ModelRatio): 모델 자체의 기본 과금 배수를 정의합니다 - Completion Ratio(
CompletionRatio): 출력 token의 가격을 별도로 조정합니다 - Cache Ratio(
CacheRatio): 캐시 적중된 입력 token의 가격을 별도로 조정합니다 - Group Ratio(
GroupRatio): 서로 다른 분组에 대해 차등 과금을 설정합니다
Quota와 Ratio의 관계
MoleAPI에서는 최종 차감 금액이 모두 Quota 포인트로 환산됩니다.
1달러 = 500,000 Quota 포인트- 사용자 잔액과 소비 기록은 본질적으로 Quota 포인트의 증감입니다
- 로그에서는 달러 기준 상세 내역이 흔히 표시되며, 백엔드에서 최종적으로 Quota 포인트로 다시 환산하여 차감합니다
Quota 계산식
사용량 기반 과금 모델(캐시 적중 없음)
Quota 소모 = (입력 token 수 + 출력 token 수 × Completion Ratio) × 모델 Ratio × Group Ratio사용량 기반 과금 모델(캐시 적중 있음)
캐시가 적중되더라도 "Cache Ratio"를 총액에 추가로 곱하는 것이 아니라, 캐시 적중된 입력 token 부분에만 적용합니다.
Quota 소모 = (일반 입력 token 수 + 캐시 token 수 × Cache Ratio + 출력 token 수 × Completion Ratio) × 모델 Ratio × Group Ratio호출 횟수 기반 과금 모델(고정 가격)
Quota 소모 = 모델 고정 가격 × Group Ratio × 500,000오디오 모델(특수 처리, new-api 내부에서 자동 처리)
Quota 소모 = (텍스트 입력 token + 텍스트 출력 token × Completion Ratio + 오디오 입력 token × 오디오 Ratio + 오디오 출력 token × 오디오 Ratio × 오디오 Completion Ratio) × 모델 Ratio × Group Ratio선차감과 후정산 메커니즘
MoleAPI는 선차감과 후정산의 2단계 과금 방식을 사용합니다.
- 선차감: 요청 전송 전에 예상 token 기준으로 먼저 차감
- 후정산: 요청 종료 후 실제 token 기준으로 재계산
- 차액 조정: 실제 비용과 선차감 비용이 일치하지 않으면 자동으로 추가 차감 또는 환급
선차감 Quota = 예상 token 수 × 모델 Ratio × Group Ratio
실제 Quota = 실제 token 수 × 모델 Ratio × Group Ratio
Quota 조정 = 실제 Quota - 선차감 Quota모델 Ratio 설정
모델 Ratio는 서로 다른 AI 모델의 기본 과금 배수를 정의하며, 시스템은 일반적인 모델에 대해 기본값을 미리 제공합니다.
일반적인 모델 Ratio 예시
| 모델명 | 모델 Ratio | Completion Ratio | 공식 가격(입력) | 공식 가격(출력) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
Ratio의 의미는 다음과 같이 이해할 수 있습니다.
- 모델 Ratio가 높을수록 전체 기본 비용이 높습니다
- Completion Ratio가 높을수록 출력 token이 더 비쌉니다
- Cache Ratio가 낮을수록 캐시 적중 시 더 절약됩니다
- Group Ratio가 낮을수록 사용자에게 최종적으로 부과되는 실제 차감액이 더 낮습니다
Completion Ratio 설정
Completion Ratio는 출력 token에 대해 추가 과금을 적용하는 데 사용되며, 주된 목적은 "출력이 입력보다 더 비싸다"는 실제 비용 차이를 반영하는 것입니다.
기본 Completion Ratio
| 모델 유형 | 공식 가격(입력) | 공식 가격(출력) | Completion Ratio | 설명 |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | 출력은 입력의 4배 |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | 출력은 입력의 2배 |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | 출력은 입력의 8배 |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | 출력은 입력의 4배 |
| 기타 모델 | 1 | 1 | 1 | 입력/출력을 동일하게 과금 |
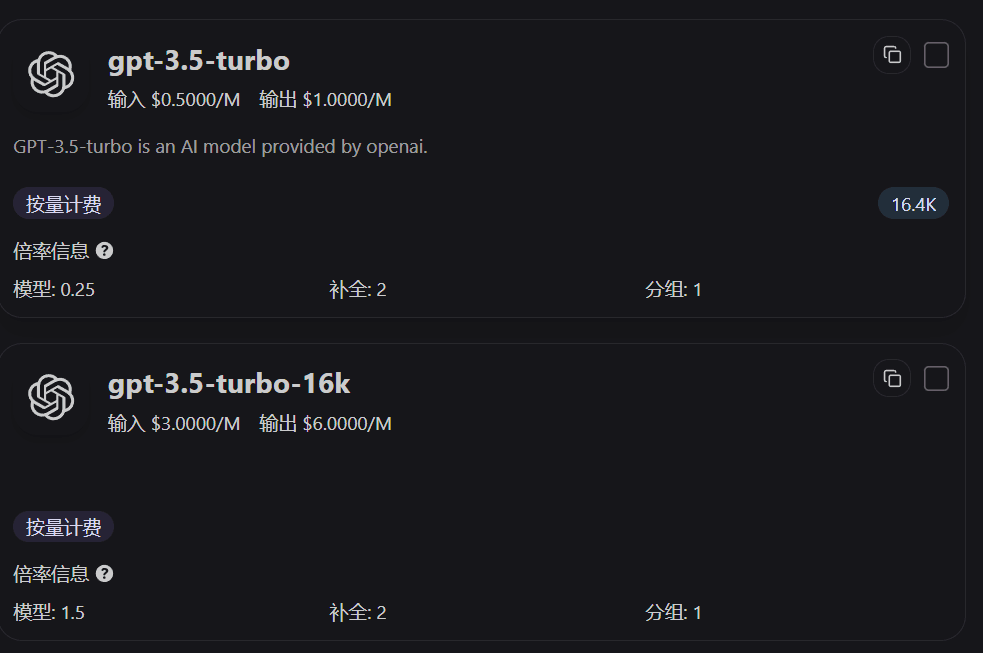
가격 페이지에서 Ratio를 보는 방법
가격 페이지의 모델 카드에는 모델 Ratio, Completion Ratio, Group Ratio가 직접 표시됩니다. 먼저 이 세 값을 보면 "같은 한 번의 호출인데 왜 이 모델이 다른 모델보다 더 비싼가"를 빠르게 판단할 수 있습니다.
Cache Ratio 설정
Cache Ratio는 많은 사용자가 처음 로그를 볼 때 가장 쉽게 오해하는 부분입니다.
Cache Ratio는 정확히 어디에 적용되나
이 값은 캐시 적중된 입력 token에만 적용되며, 다음에는 적용되지 않습니다.
- 캐시가 적중되지 않은 일반 입력 token
- 출력 token
- 요청 전체의 총액
즉, 하나의 요청에 일반 입력과 캐시 입력이 동시에 존재한다면, 각각 다른 가격으로 계산한 뒤 마지막에 Group Ratio를 함께 곱합니다.
언제 로그에서 Cache Ratio를 볼 수 있나
업스트림 모델이 프롬프트 캐시를 지원하고, 해당 요청에서 실제로 캐시가 적중되었다면 로그에 보통 다음 항목이 추가로 표시됩니다.
缓存 Tokens缓存倍率缓存价格
캐시가 적중되지 않았다면 이 몇 줄은 최종 비용 계산에 포함되지 않습니다.
Group Ratio 설정
Group Ratio를 사용하면 서로 다른 Channel 분组별로 차등 가격을 설정할 수 있으며, 예를 들어 기본 그룹, 할인 그룹, Relay 그룹, 체험 그룹 등 서로 다른 전략을 구현할 수 있습니다.
Group Ratio 구성
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}Q: Group Ratio는 어떻게 적용되나요?
A: Group Ratio는 마지막 단계에서 요청 전체에 일괄 적용됩니다. 즉, "최종적으로 사용자에게 적용되는 가격 계수"로 이해하면 됩니다.
Q: Completion Ratio의 역할은 무엇인가요?
A: Completion Ratio는 주로 입력 token과 출력 token의 비용 차이를 균형 있게 반영하기 위해 사용됩니다. 많은 모델에서 출력 가격이 입력 가격보다 분명히 높기 때문에, 로그에서는 출력 token을 Completion Ratio로 별도 환산해 계산합니다.
Q: Cache Ratio의 역할은 무엇인가요?
A: Cache Ratio는 캐시 적중된 입력 token에만 영향을 줍니다. Cache Ratio가 낮을수록 캐시 적중 시 해당 token 부분의 실제 비용이 더 낮아집니다.
QA 계산 예시
아래 예시는 추상적인 공식이 아니라, 로그에 있는 필드를 기준으로 단계별로 직접 계산한 것입니다.
Q1: 캐시가 포함된 요청에서는 왜 로그에 "缓存价格" 한 줄이 추가되나요?
이번 요청에서 캐시가 적중되었기 때문에 시스템은 입력 token을 두 부분으로 나누어 계산합니다.
- 일반 입력 token: 입력 가격으로 계산
- 캐시 적중 token: 입력 가격에 Cache Ratio를 곱해 계산
아래 로그에서는 缓存 Tokens 3072, 缓存倍率 1, 缓存价格를 확인할 수 있습니다.

로그의 숫자를 기준으로 계산하면 다음과 같습니다.
입력 비용 = 62 / 1M × $0.250000 = $0.0000155
캐시 비용 = 3072 / 1M × $0.250000 = $0.000768
출력 비용 = 1193 / 1M × $2.000000 = $0.002386
최종 비용 = (입력 비용 + 캐시 비용 + 출력 비용) × Group Ratio 1
= $0.0031695
≈ $0.003170이를 Quota 포인트로 환산하면 대략 다음과 같습니다.
$0.003170 × 500,000 ≈ 1,585 Quota 포인트Q2: 캐시 적중이 없을 때는 비용을 어떻게 확인해야 하나요?
캐시 적중이 없다면 일반 입력과 출력 두 부분만 보면 되며, 캐시 가격은 나타나지 않습니다.

로그의 필드를 기준으로 계산하면 다음과 같습니다.
입력 비용 = 827 / 1M × $0.250000 = $0.00020675
출력 비용 = 338 / 1M × $2.000000 = $0.000676
최종 비용 = (입력 비용 + 출력 비용) × Group Ratio 1
= $0.00088275
≈ $0.000883Quota 포인트로 환산하면 대략 다음과 같습니다.
$0.000883 × 500,000 ≈ 441 Quota 포인트Q3: Cache Ratio와 Group Ratio가 동시에 있을 때는 무엇을 먼저 계산해야 하나요?
먼저 입력, 캐시, 출력 세 부분의 비용을 각각 계산한 다음, 마지막에 Group Ratio를 일괄 적용합니다. 아래 로그에는 다음 값이 동시에 포함되어 있습니다.
- 모델 Ratio
1.25 - Cache Ratio
0.1 - 출력 Ratio
6 - Group Ratio
0.3

로그의 가격 상세를 기준으로 계산하면 다음과 같습니다.
일반 입력 비용 = 357360 / 1M × $2.500000 = $0.893400
캐시 비용 = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
출력 비용 = 100 / 1M × $15.000000 = $0.001500
최종 비용 = (일반 입력 비용 + 캐시 비용 + 출력 비용) × Group Ratio 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736이 때문에 로그에는 다음 항목이 별도로 표시됩니다.
- 입력 가격:
$2.500000 / 1M tokens - 출력 가격:
$15.000000 / 1M tokens - 캐시 가격:
$2.500000 × 0.1 = $0.250000 / 1M tokens
Q4: Ratio를 보고 모델 카드가 대략 비싼지 아닌지 어떻게 판단하나요?
가장 간단한 순서는 다음과 같습니다.
- 먼저 모델 Ratio를 보고 이 모델의 기본 비용이 높은지 판단합니다
- 다음으로 Completion Ratio를 보고 출력 내용이 눈에 띄게 더 비쌀지 판단합니다
- 모델이 캐시를 지원한다면 Cache Ratio를 보고 캐시 적중 후 얼마나 절약되는지 판단합니다
- 마지막으로 Group Ratio를 보고 현재 분组에서 실제 사용자 대상 가격이 어떻게 적용되는지 판단합니다
가격 페이지에서 어떤 모델이 다음과 같다면,
- 모델 Ratio가 높고
- Completion Ratio가 높고
- Group Ratio도 높다면
긴 출력이 많은 시나리오에서 일반적으로 더 비싸집니다. 반대로 Cache Ratio가 낮고 캐시 적중률이 높다면, 이러한 요청의 실제 비용은 더 눈에 띄게 낮아집니다.
더 많은 과금 규칙은 자주 묻는 질문에서 확인하세요.
이 문서가 도움이 되었나요?
마지막 업데이트