Comprendre les ratios
La configuration des ratios est le paramètre central du système de facturation de MoleAPI. Une fois que vous comprenez le ratio du modèle, le ratio de completion, le ratio de cache et le ratio de groupe, vous pouvez interpréter les informations de ratio sur la page de tarification et vérifier rapidement, à partir des logs, pourquoi une requête a consommé autant.
Vue d’ensemble du système de ratios
MoleAPI utilise quatre types de ratios pour calculer la consommation de quota de l’utilisateur :
- Ratio du modèle (
ModelRatio) : définit le multiplicateur de facturation de base du modèle lui-même - Ratio de completion (
CompletionRatio) : ajuste séparément le prix des tokens de sortie - Ratio de cache (
CacheRatio) : ajuste séparément le prix des tokens d’entrée servis depuis le cache - Ratio de groupe (
GroupRatio) : définit une facturation différenciée selon les groupes
Relation entre quota et ratios
Dans MoleAPI, la facturation finale est uniformément convertie en points de quota.
1 dollar = 500,000 points de quota- Le solde utilisateur et l’historique de consommation correspondent essentiellement à des augmentations ou diminutions de points de quota
- Dans les logs, les détails sont souvent affichés en dollars, puis le backend les reconvertit finalement en points de quota à déduire
Formules de calcul du quota
Modèle facturé à l’usage (sans cache hit)
Consommation de quota = (nombre de tokens d’entrée + nombre de tokens de sortie × ratio de completion) × ratio du modèle × ratio de groupeModèle facturé à l’usage (avec cache hit)
En cas de cache hit, le « ratio de cache » n’est pas appliqué en multiplicateur supplémentaire au prix total ; il ne s’applique qu’à la partie des tokens d’entrée servis depuis le cache.
Consommation de quota = (nombre de tokens d’entrée ordinaires + nombre de tokens du cache × ratio de cache + nombre de tokens de sortie × ratio de completion) × ratio du modèle × ratio de groupeModèle facturé à l’appel (prix fixe)
Consommation de quota = prix fixe du modèle × ratio de groupe × 500,000Modèle audio (traitement spécial, géré automatiquement en interne par new-api)
Consommation de quota = (tokens d’entrée texte + tokens de sortie texte × ratio de completion + tokens d’entrée audio × ratio audio + tokens de sortie audio × ratio audio × ratio de completion audio) × ratio du modèle × ratio de groupeMécanisme de pré-consommation et de post-consommation
MoleAPI utilise une facturation en deux étapes : pré-consommation puis post-consommation :
- Pré-consommation : avant l’envoi de la requête, une déduction anticipée est effectuée sur la base d’une estimation du nombre de tokens
- Post-consommation : après la fin de la requête, le calcul est refait sur la base du nombre réel de tokens
- Ajustement du différentiel : si le coût réel diffère du montant prélevé à l’avance, le système effectue automatiquement un débit complémentaire ou un remboursement
Quota pré-consommé = nombre estimé de tokens × ratio du modèle × ratio de groupe
Quota réel = nombre réel de tokens × ratio du modèle × ratio de groupe
Ajustement du quota = quota réel - quota pré-consomméConfiguration du ratio du modèle
Le ratio du modèle définit le multiplicateur de facturation de base des différents modèles d’IA. Le système fournit des valeurs par défaut pour les modèles courants.
Exemples de ratios pour des modèles courants
| Nom du modèle | Ratio du modèle | Ratio de completion | Prix officiel (entrée) | Prix officiel (sortie) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
La signification des ratios peut être comprise ainsi :
- Plus le ratio du modèle est élevé, plus le coût de base global est élevé
- Plus le ratio de completion est élevé, plus les tokens de sortie sont chers
- Plus le ratio de cache est faible, plus un cache hit permet d’économiser
- Plus le ratio de groupe est faible, plus la déduction finale appliquée à l’utilisateur est faible
Configuration du ratio de completion
Le ratio de completion permet de facturer en supplément les tokens de sortie, principalement pour refléter la différence de coût réelle selon laquelle « la sortie est plus chère que l’entrée ».
Ratio de completion par défaut
| Type de modèle | Prix officiel (entrée) | Prix officiel (sortie) | Ratio de completion | Description |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | La sortie coûte 4 fois l’entrée |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | La sortie coûte 2 fois l’entrée |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | La sortie coûte 8 fois l’entrée |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | La sortie coûte 4 fois l’entrée |
| Autres modèles | 1 | 1 | 1 | Facturation équivalente entrée/sortie |
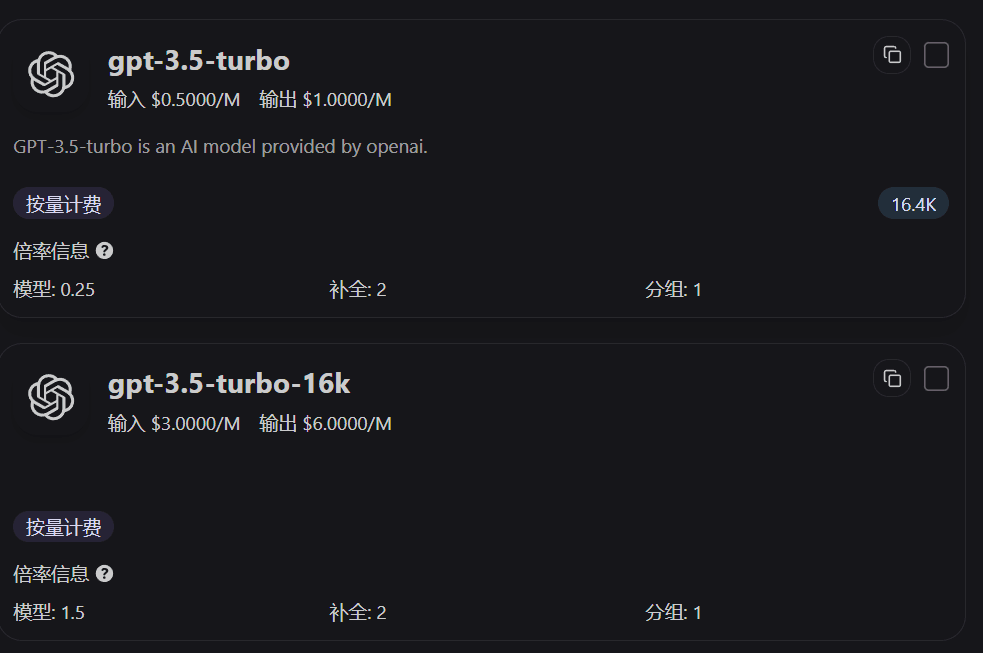
Comment lire les ratios sur la page de tarification
Les cartes de modèles sur la page de tarification affichent directement le ratio du modèle, le ratio de completion et le ratio de groupe. En consultant d’abord ces trois valeurs, vous pouvez rapidement comprendre pourquoi, à appel identique, un modèle est plus cher qu’un autre.
Configuration du ratio de cache
Le ratio de cache est l’un des points les plus facilement mal compris lorsqu’on consulte les logs pour la première fois.
À quoi s’applique exactement le ratio de cache
Il ne s’applique qu’aux tokens d’entrée servis depuis le cache, et ne s’applique pas :
- aux tokens d’entrée ordinaires qui ne proviennent pas du cache
- aux tokens de sortie
- au prix total de l’ensemble de la requête
Autrement dit, si une requête contient à la fois des entrées ordinaires et des entrées servies depuis le cache, elles sont calculées séparément avec des prix différents, puis multipliées ensemble par le ratio de groupe.
Quand verrez-vous le ratio de cache dans les logs
Lorsque le modèle amont prend en charge le prompt cache et que cette requête a effectivement produit un cache hit, les logs affichent généralement en plus :
缓存 Tokens缓存倍率缓存价格
S’il n’y a pas de cache hit, ces lignes ne participent pas au calcul du coût final.
Configuration du ratio de groupe
Le ratio de groupe permet de définir des prix différenciés selon les groupes de Channel, afin de mettre en place différentes stratégies, par exemple groupe par défaut, groupe remisé, groupe de relay, groupe d’essai, etc.
Configuration du ratio de groupe
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}Q : Comment le ratio de groupe s’applique-t-il ?
R : Le ratio de groupe s’applique uniformément à l’ensemble de la requête à la dernière étape. Vous pouvez le comprendre comme le « coefficient de prix final côté utilisateur ».
Q : Quel est le rôle du ratio de completion ?
R : Le ratio de completion sert principalement à équilibrer la différence de coût entre les tokens d’entrée et de sortie. Pour de nombreux modèles, le prix de sortie est nettement supérieur au prix d’entrée ; c’est pourquoi les logs recalculent séparément les tokens de sortie selon le ratio de completion.
Q : Quel est le rôle du ratio de cache ?
R : Le ratio de cache n’affecte que les tokens d’entrée ayant produit un cache hit. Plus le ratio de cache est faible, plus le coût réel de cette partie des tokens est bas lorsqu’il y a cache hit.
Exemples de calcul Q/R
Les exemples ci-dessous ne sont pas des formules abstraites : ils montrent un calcul étape par étape directement à partir des champs figurant dans les logs.
Q1 : Pourquoi une requête avec cache affiche-t-elle une ligne « prix du cache » supplémentaire dans les logs ?
Parce que cette requête a produit un cache hit, le système a séparé les tokens d’entrée en deux parties :
- Tokens d’entrée ordinaires : calculés au prix d’entrée
- Tokens d’entrée servis depuis le cache : calculés au prix d’entrée puis multipliés par le ratio de cache
Le log ci-dessous montre 缓存 Tokens 3072, 缓存倍率 1 et 缓存价格 :

D’après les chiffres du log, le calcul est le suivant :
Coût d’entrée = 62 / 1M × $0.250000 = $0.0000155
Coût du cache = 3072 / 1M × $0.250000 = $0.000768
Coût de sortie = 1193 / 1M × $2.000000 = $0.002386
Coût final = (coût d’entrée + coût du cache + coût de sortie) × ratio de groupe 1
= $0.0031695
≈ $0.003170Converti en points de quota, cela donne environ :
$0.003170 × 500,000 ≈ 1,585 points de quotaQ2 : Comment vérifier le coût lorsqu’il n’y a pas de cache hit ?
Lorsqu’il n’y a pas de cache hit, il suffit de regarder les deux parties : entrée ordinaire et sortie. Aucun prix du cache n’apparaît.

Les champs du log correspondent au calcul suivant :
Coût d’entrée = 827 / 1M × $0.250000 = $0.00020675
Coût de sortie = 338 / 1M × $2.000000 = $0.000676
Coût final = (coût d’entrée + coût de sortie) × ratio de groupe 1
= $0.00088275
≈ $0.000883Converti en points de quota, cela donne environ :
$0.000883 × 500,000 ≈ 441 points de quotaQ3 : Lorsque le ratio de cache et le ratio de groupe existent en même temps, lequel faut-il calculer en premier ?
Il faut d’abord calculer séparément les coûts des trois parties : entrée, cache et sortie, puis appliquer uniformément le ratio de groupe. Le log ci-dessous contient simultanément :
- Ratio du modèle
1.25 - Ratio de cache
0.1 - Ratio de sortie
6 - Ratio de groupe
0.3

Vérification à partir du détail des prix dans le log :
Coût d’entrée ordinaire = 357360 / 1M × $2.500000 = $0.893400
Coût du cache = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
Coût de sortie = 100 / 1M × $15.000000 = $0.001500
Coût final = (coût d’entrée ordinaire + coût du cache + coût de sortie) × ratio de groupe 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736C’est aussi la raison pour laquelle les logs affichent séparément :
- Prix d’entrée :
$2.500000 / 1M tokens - Prix de sortie :
$15.000000 / 1M tokens - Prix du cache :
$2.500000 × 0.1 = $0.250000 / 1M tokens
Q4 : Comment estimer rapidement si une carte de modèle est chère à partir des ratios ?
L’ordre le plus simple est :
- Vérifier d’abord le ratio du modèle pour juger si le coût de base du modèle est élevé
- Vérifier ensuite le ratio de completion pour voir si le contenu généré en sortie sera nettement plus cher
- Si le modèle prend en charge le cache, vérifier ensuite le ratio de cache pour estimer l’économie réalisée en cas de cache hit
- Enfin, vérifier le ratio de groupe pour connaître le prix réel appliqué à l’utilisateur dans votre groupe actuel
Si, sur la page de tarification, vous voyez qu’un modèle a :
- un ratio du modèle élevé
- un ratio de completion élevé
- un ratio de groupe également élevé
alors, dans les scénarios avec de longues sorties, il sera généralement nettement plus cher. À l’inverse, si le ratio de cache est faible et que le taux de cache hit est élevé, le coût réel de ce type de requêtes diminuera de manière plus visible.
Pour plus de règles de facturation, consultez la FAQ
Ce guide vous a-t-il aidé ?
Dernière mise à jour le
Paramètres de notification et alertes de quota
Recevoir à l’avance des alertes sur le solde ou les anomalies est plus important que d’attendre qu’un problème de service survienne avant d’enquêter
Démarrage rapide pour les développeurs
Effectuez votre premier appel minimal viable à l’aide d’une interface compatible OpenAI