Comprender los Ratios
La configuración de ratios es la parte central del sistema de facturación de MoleAPI. Después de entender el ratio del modelo, el ratio de completion, el ratio de caché y el ratio de grupo, podrás interpretar la información de ratios en la página de precios y también verificar rápidamente, a partir de los logs, por qué una solicitud ha consumido tanto.
Resumen del sistema de Ratios
MoleAPI utiliza cuatro tipos de Ratio para calcular el consumo de quota del usuario:
- Ratio del modelo (
ModelRatio): define el multiplicador base de facturación del propio modelo - Ratio de completion (
CompletionRatio): ajusta por separado el precio de los token de salida - Ratio de caché (
CacheRatio): ajusta por separado el precio de los token de entrada con acierto de caché - Ratio de grupo (
GroupRatio): establece una facturación diferenciada para distintos grupos
Relación entre quota y Ratio
En MoleAPI, el cargo final se convierte de forma unificada en puntos de quota.
1 dólar = 500,000 puntos de quota- El saldo del usuario y los registros de consumo son, en esencia, aumentos y disminuciones de puntos de quota
- En los logs es habitual ver el detalle en dólares, pero el sistema finalmente lo convierte de nuevo a puntos de quota para realizar la deducción
Fórmulas de cálculo de quota
Modelos con facturación por uso (sin acierto de caché)
Consumo de quota = (número de token de entrada + número de token de salida × ratio de completion) × ratio del modelo × ratio de grupoModelos con facturación por uso (con acierto de caché)
Cuando hay acierto de caché, el “ratio de caché” no se multiplica adicionalmente sobre el precio total, sino que solo se aplica a la parte correspondiente a los token de entrada en caché.
Consumo de quota = (número de token de entrada normales + número de token en caché × ratio de caché + número de token de salida × ratio de completion) × ratio del modelo × ratio de grupoModelos con facturación por solicitud (precio fijo)
Consumo de quota = precio fijo del modelo × ratio de grupo × 500,000Modelos de audio (tratamiento especial, procesado automáticamente de forma interna por new-api)
Consumo de quota = (token de entrada de texto + token de salida de texto × ratio de completion + token de entrada de audio × ratio de audio + token de salida de audio × ratio de audio × ratio de completion de audio) × ratio del modelo × ratio de grupoMecanismo de preconsumo y posconsumo
MoleAPI adopta un sistema de facturación en dos fases: preconsumo y posconsumo:
- Preconsumo: antes de enviar la solicitud, se realiza una deducción previa según los token estimados
- Posconsumo: al finalizar la solicitud, se recalcula según los token reales
- Ajuste de diferencia: si el coste real no coincide con el coste preconsumido, el sistema compensa automáticamente cobrando o reembolsando la diferencia
Quota de preconsumo = número estimado de token × ratio del modelo × ratio de grupo
Quota real = número real de token × ratio del modelo × ratio de grupo
Ajuste de quota = quota real - quota de preconsumoConfiguración del ratio del modelo
El ratio del modelo define el multiplicador base de facturación de distintos modelos de AI. El sistema preconfigura valores predeterminados para los modelos más comunes.
Ejemplos de ratios de modelos habituales
| Nombre del modelo | Ratio del modelo | Ratio de completion | Precio oficial (entrada) | Precio oficial (salida) |
|---|---|---|---|---|
| gpt-4o | 1.25 | 4 | $2.5/1M Tokens | $10/1M Tokens |
| gpt-3.5-turbo | 0.25 | 2 | $0.5/1M Tokens | $1.0/1M Tokens |
| gpt-4o-mini | 0.075 | 4 | $0.15/1M Tokens | $0.6/1M Tokens |
| o1 | 7.5 | 4 | $15/1M Tokens | $60/1M Tokens |
El significado de los ratios puede entenderse así:
- Cuanto mayor sea el ratio del modelo, mayor será el coste base global
- Cuanto mayor sea el ratio de completion, más caros serán los token de salida
- Cuanto menor sea el ratio de caché, mayor será el ahorro cuando haya acierto de caché
- Cuanto menor sea el ratio de grupo, menor será el cargo final real para el usuario
Configuración del ratio de completion
El ratio de completion se utiliza para aplicar un cargo adicional a los token de salida, principalmente para reflejar la diferencia real de costes según la cual “la salida es más cara que la entrada”.
Ratio de completion predeterminado
| Tipo de modelo | Precio oficial (entrada) | Precio oficial (salida) | Ratio de completion | Descripción |
|---|---|---|---|---|
| gpt-4o | $2.5/1M Tokens | $10/1M Tokens | 4 | La salida cuesta 4 veces más que la entrada |
| gpt-3.5-turbo | $0.5/1M Tokens | $1.0/1M Tokens | 2 | La salida cuesta 2 veces más que la entrada |
| gpt-image-1 | $5/1M Tokens | $40/1M Tokens | 8 | La salida cuesta 8 veces más que la entrada |
| gpt-4o-mini | $0.15/1M Tokens | $0.6/1M Tokens | 4 | La salida cuesta 4 veces más que la entrada |
| Otros modelos | 1 | 1 | 1 | La entrada y la salida se facturan por igual |
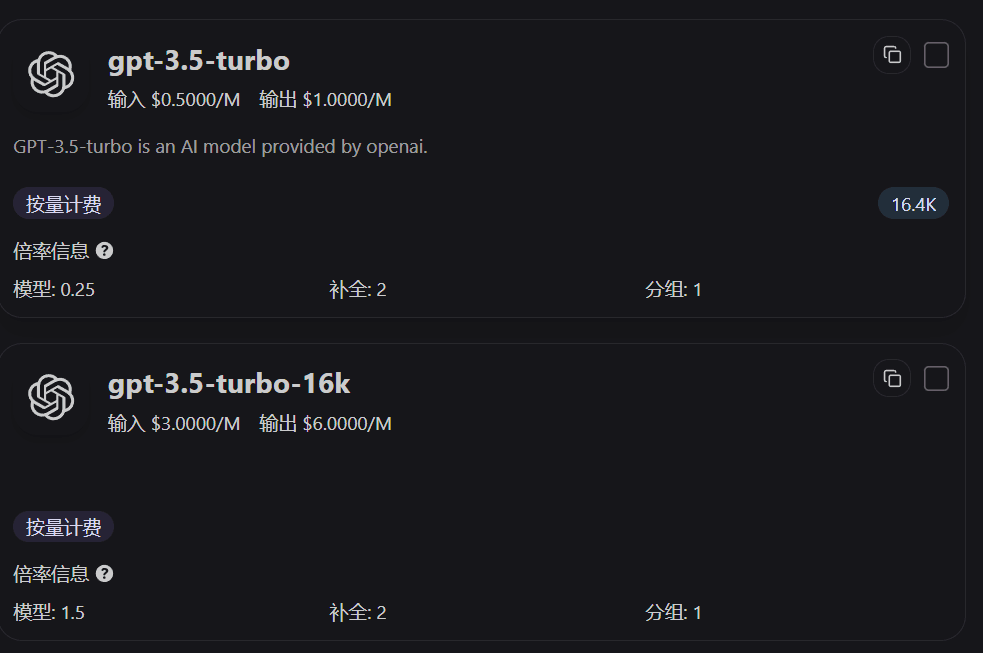
Cómo interpretar los ratios en la página de precios
Las tarjetas de modelo en la página de precios muestran directamente el ratio del modelo, el ratio de completion y el ratio de grupo. Con solo revisar estos tres valores, puedes entender rápidamente por qué “la misma llamada resulta más cara en este modelo que en otro”.
Configuración del ratio de caché
El ratio de caché es uno de los puntos que más se malinterpretan la primera vez que se revisan los logs.
¿Dónde se aplica exactamente el ratio de caché?
Solo se aplica a los token de entrada con acierto de caché; no se aplica a:
- token de entrada normales sin acierto de caché
- token de salida
- el precio total de toda la solicitud
Es decir, si en una misma solicitud hay tanto entrada normal como entrada en caché, ambas se calculan por separado con precios distintos y luego se multiplican conjuntamente por el ratio de grupo.
¿Cuándo verás el ratio de caché en los logs?
Cuando el modelo upstream admite prompt caching y la solicitud realmente acierta en caché, en los logs normalmente aparecerán además:
缓存 Tokens缓存倍率缓存价格
Si no hay acierto de caché, estas líneas no participarán en el cálculo del coste final.
Configuración del ratio de grupo
El ratio de grupo permite establecer precios diferenciados para distintos grupos de Channel, para aplicar estrategias como grupo predeterminado, grupo con descuento, grupo de relay, grupo de prueba, etc.
Configuración del ratio de grupo
{
"default": 1,
"discount": 0.8,
"relay": 0.3,
"trial": 0.1
}P: ¿Cómo entra en vigor el ratio de grupo?
R: El ratio de grupo se aplica de forma unificada sobre toda la solicitud en la fase final. Puedes entenderlo como el “coeficiente de precio final para el usuario”.
P: ¿Cuál es la función del ratio de completion?
R: El ratio de completion se usa principalmente para equilibrar la diferencia de coste entre token de entrada y token de salida. En muchos modelos, el precio de salida es claramente superior al de entrada, por lo que en los logs los token de salida se convierten por separado mediante el ratio de completion.
P: ¿Cuál es la función del ratio de caché?
R: El ratio de caché solo afecta a los token de entrada con acierto de caché. Cuanto menor sea el ratio de caché, menor será el coste real de esa parte de token cuando haya acierto de caché.
Ejemplos de cálculo en QA
Los siguientes ejemplos no son fórmulas abstractas, sino cálculos paso a paso directamente a partir de los campos de los logs.
Q1: En una solicitud con caché, ¿por qué aparece una línea adicional de “precio de caché” en los logs?
Porque esta solicitud ha tenido acierto de caché, y el sistema ha dividido los token de entrada en dos partes:
- token de entrada normales: se calculan con el precio de entrada
- token de entrada con acierto de caché: se calculan con el precio de entrada multiplicado por el ratio de caché
En el siguiente log se pueden ver 缓存 Tokens 3072, 缓存倍率 1 y 缓存价格:

Según las cifras del log, el cálculo es:
Coste de entrada = 62 / 1M × $0.250000 = $0.0000155
Coste de caché = 3072 / 1M × $0.250000 = $0.000768
Coste de salida = 1193 / 1M × $2.000000 = $0.002386
Coste final = (coste de entrada + coste de caché + coste de salida) × ratio de grupo 1
= $0.0031695
≈ $0.003170Si se convierte a puntos de quota, sería aproximadamente:
$0.003170 × 500,000 ≈ 1,585 puntos de quotaQ2: Cuando no hay acierto de caché, ¿cómo debe verificarse el coste?
Si no hay acierto de caché, solo hay que revisar las dos partes de entrada normal y salida; no aparecerá precio de caché.

Los campos del log corresponden al siguiente cálculo:
Coste de entrada = 827 / 1M × $0.250000 = $0.00020675
Coste de salida = 338 / 1M × $2.000000 = $0.000676
Coste final = (coste de entrada + coste de salida) × ratio de grupo 1
= $0.00088275
≈ $0.000883Convertido a puntos de quota, sería aproximadamente:
$0.000883 × 500,000 ≈ 441 puntos de quotaQ3: Cuando existen al mismo tiempo ratio de caché y ratio de grupo, ¿cuál debe calcularse primero?
Primero se calculan por separado los costes de entrada, caché y salida, y después se multiplica todo de forma unificada por el ratio de grupo. El siguiente log incluye al mismo tiempo:
- ratio del modelo
1.25 - ratio de caché
0.1 - ratio de salida
6 - ratio de grupo
0.3

Verificando según el desglose de precios del log:
Coste de entrada normal = 357360 / 1M × $2.500000 = $0.893400
Coste de caché = 30208 / 1M × ($2.500000 × 0.1) = $0.007552
Coste de salida = 100 / 1M × $15.000000 = $0.001500
Coste final = (coste de entrada normal + coste de caché + coste de salida) × ratio de grupo 0.3
= ($0.893400 + $0.007552 + $0.001500) × 0.3
= $0.2707356
≈ $0.270736Por eso, en el log también se muestra por separado:
- precio de entrada:
$2.500000 / 1M tokens - precio de salida:
$15.000000 / 1M tokens - precio de caché:
$2.500000 × 0.1 = $0.250000 / 1M tokens
Q4: ¿Cómo estimar rápidamente, a partir de los ratios, si una tarjeta de modelo es cara o no?
El orden más sencillo es:
- Revisar primero el ratio del modelo para determinar si el coste base del modelo es alto
- Revisar después el ratio de completion para determinar si la salida será claramente más cara
- Si el modelo admite caché, revisar el ratio de caché para estimar cuánto se ahorra cuando hay acierto de caché
- Por último, revisar el ratio de grupo para determinar el precio real que se aplica al usuario en tu grupo actual
Si en la página de precios ves un modelo con:
- ratio del modelo alto
- ratio de completion alto
- ratio de grupo también alto
entonces, en escenarios con mucha salida, normalmente será claramente más caro; por el contrario, si el ratio de caché es bajo y la tasa de acierto de caché es alta, el coste real de este tipo de solicitudes disminuirá de forma mucho más notable.
Para más reglas de facturación, consulta las Preguntas frecuentes
¿Te resultó útil esta guía?
Última actualización el
Configuración de notificaciones y alertas de quota
Recibir avisos por saldo bajo o anomalías con antelación es más importante que esperar a que el servicio falle para empezar a investigar
Inicio rápido para desarrolladores
Completa tu primera llamada mínima funcional usando una interfaz compatible con OpenAI